A programmer's site
点点滴滴:生活,技术
点点滴滴:生活,技术
我们正在招聘,需要Android和iOS工程师的加入,和我一组,开发看准网 的App,为四亿职场人服务。 请发简历 到 shenfeng at kanzhun dot com,请加入我们
上个月,介绍了生成Java JDBC访问代码,从SQL文件,后面应用到我负责的几个实际的项目,效果不错, 程序清清了很多,也更好维护。
用类似的思路,我做了一个新的工具: api-kit,移动开发从中受益。
移动开发,下面几个环节免不了:
这里面有一些重复: 负责server的同学开发API后,写文档是把同样的信息,表达了两次,一次是在code里面,一次在文档。 客户端同学实现各自平台的访问代码,是重复,因为这部分信息是server端的code(或者文档)的一次翻译(跨语言,跨平台)。
这几天,我写了一个程序,api-kit,通过自动生成代码的方式,解决这里面的大部分重复,使信息的流动更高效和快捷。
假设API描述是这样的:
// 这是api-kit的输入,输出是各个平台的code:Android, iOS, Server端
struct Book {
i32 id
string title
string isbn
float32 price
string description
}
@url(/books/newest)
@get
func list<Book> getNewest(i32 limit, i32 offset);
@url(/books/search)
@get
func list<Book> searchBook(string q, i32 limit, i32 offset);API描述是api-kit的输入,输出是各个平台(Server,Android, iOS)的code。
public interface IHandler {
// Called before every function. Use cases: setup context, authentication return false to abort further execution.
public boolean before(Context context);
// Called after every function. One use case is logging
public void after(Context context);
// GET /api/books/newest
public List<Book> GetNewest(Context context, int limit, int offset);
// GET /api/books/search
public List<Book> SearchBook(Context context, String q, int limit, int offset);
}
服务器端的工作简化为实现这个Interface生成的code,处理url拼接,返回值解析,暴露给程序员的是函数:
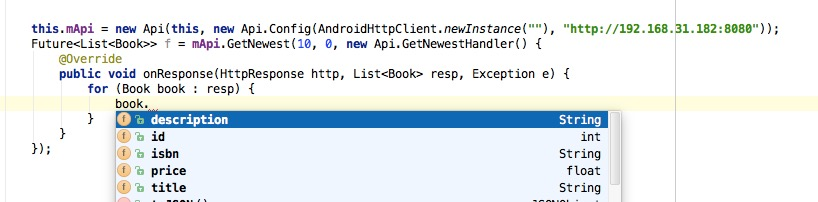
零依赖,能有效的减少apk的体积。在compiler的帮助下,做到类型安全,服务器重构后,这边会编译出错,refactor会方便一些。
iOS显然是需要支持的。先花了一天时间,学习swift,并完成swift的code生成。在和公司的iOS工程师沟通时,他们在用objective-c, 于是又多花了一天时间看oc,并生成oc的code,语法有点不太习惯,但还是搞定了。
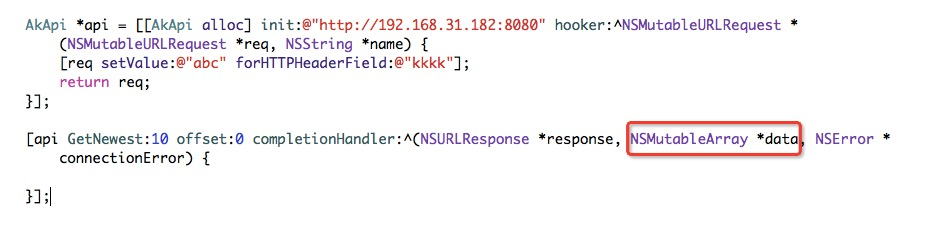
也是零依赖的,能有效的减少app的体积。由于oc支持类型安全的dict和arr挺困难,于是,通过注释帮助一点。

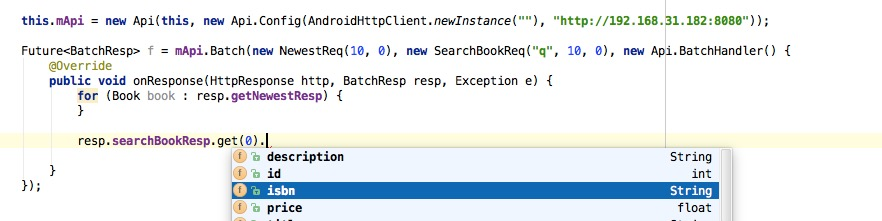
由于移动的特殊性(latency),一个页面一般需要请求多次,才能render。请求多用异步,多个异步的嵌套挺不方便, 如果能合并这些请求,移动端的开发会更方便,也会提高性能。api-kit透明的实现了这一点。
ns com.kanzhun.api
struct Book {
i32 id
string title
string isbn
float32 price
string description
}
struct NewestReq {
i32 limit
i32 offset
}
struct SearchBookReq {
string q
i32 limit
i32 offset
}
@url(/books/newest)
@get
func list<Book> GetNewest(NewestReq req); // batch要求参数的个数仅为一个
@url(/books/search)
@get
func list<Book> SearchBook(SearchBookReq req);
// `batch` 为关键字
// GetNewest, SearchBook 都是函数名
// batch请求,和服务端是一次交互,客户端发送一次请求给服务端
@url(/batch)
batch Batch(GetNewest, SearchBook)生成的code

我们正在招聘,需要Android和iOS工程师的加入,和我一组,开发看准网 的App,为四亿职场人服务。 请发简历 到 shenfeng at kanzhun dot com,请加入我们
通过JDBC访问数据库,相信不少人都用过。比较繁琐,有很多的boilerplate。很多聪明的程序员也发现了这个问题,通过各种方式来解决这个问题(当然,他们也为了解决另外的问题, boilerplate是其中之一),比如Hibernate,iBATIS,JdbcTemplate(Spring),等等。这几种,各有各的优劣,也有很多用户。
最近在项目中,受Thrift,以及其他一些项目启发,试着写了一个程序,来自动生成JDBC的访问代码。
SQL,表达能力强,没有多少boilerplate:
SELECT isbn, title, price, price * 0.06 AS sales_tax
FROM Book WHERE price > 100.00 ORDER BY title limit 10;我们在写程序时,可能价格是个参数,还需要支持分页(limit, offset),返回的是List, 于是就是:
func list<Book> getBooksByPrice(float price, i32 limit, i32 offset) {
SELECT isbn, title, price, price * 0.06 AS sales_tax
FROM Book WHERE price > :price ORDER BY title limit :limit, :offset;
}这段话,表达是清楚的,并且没有额外的“客套话”。 如果有一个程序,输入是上面的code,生成的code是可以直接被调用的函数,将是理想情况。
这里有个问题,Book 未定义。当然,我们可以解析SQL语句,找到它来自 Book 表,继而contact数据库,找到Book表的metadata,能找到各个字段的数据类型, 就能定义Book了。如果这里面有Join的情况,会多联系几张表。 这样引入了联系数据库的依赖,增加依赖一般是需要再三考量的。另外,解析SQL,找出字段的来源去脉,推断类型,不是一件简单的工作。
但有个折中的办法,引入一些冗余(为什么是冗余呢?因为这个Book定义的信息是可以推导出来的)
struct Book {
string isbn
string title
float price
float salesTax
}虽加入了一些冗余,貌似还可以接受。
我试着用Python写了这个程序 java-jdbc,输入是上面的代码,输出是Java代码(函数)。
运行命令
python java_jdbc.py --input example.sf --out gen-java就会在 gen-java目录生成访问数据库的代码。其中输入文件(example.sf):
namespace java me.shenfeng
struct Item {
i32 id
string name
}
// select
func Item getItemById(i32 id) {
select * form item where id = :id
}
func list<Item> getItems(int limit, int offset) {
select * from item limit :limit, :offset
}
func list<Item> getItems(list<i32> ids) {
select * from item where id in (:ids) order by FIELD(id, :ids)
}
// insert, return generated primary key
func i32 saveItem(string name) {
insert into item (name) value (:name)
}
// update
func void updateItem(i32 id, string newName) {
update item set name = :newName where id = :id
}
// delete
func void deleteItemById(i32 id) {
delete from item where id = :id
}生成的API:

相比Hibernate,iBATIS,JdbcTemplate(Spring),java-jdbc优点:
缺点:
后面的方向呀,由于这相当于定义了新的语言,可以通过扩展语言的方式,来扩展功能,比如
// 最多cache 10000,通过lru策略淘汰,每个cache时间,最多3600s。 TODO
(size=10000, expire=3600s)
func list<Book> getBooksByPrice(float price, i32 limit, i32 offset) {
SELECT isbn, title, price, price * 0.06 AS sales_tax
FROM Book WHERE price > :price ORDER BY title limit :limit, :offset;
}大年初三,走亲访友。弟弟女朋友到家串门,4人一起玩赌金花游戏打法时间。一连玩了好几把,没有赢过一次,全当陪练了:连对子都没来过。我好奇了,
第一个问题是第二个的基础。每次选择都是一种冒险(除非手握3张A,这时需要的是诱导),但需要努力做到是caculated risk。
相信是可以通过数学计算得出各类牌的概率。但对于我这样一个可以通过程序来奴役机器的程序员来说,另外一个自然的想法:让机器随机发牌,通过统计,来估算各类牌出现的概率,当然本空间足够大,统计结果会趋近理论值。
每次发4个人的牌,随机发10万次,统计40万副牌中,各类的概率分布: 
一个意外的有趣发现,牌面上,同花色比顺子大,但出现概率上,顺子更小。同样的还有同花顺和3同牌。
计算了德州扑克牌的概率分布:它的9种类别的牌的概率,严格按照递增顺序。似乎设计赌金花的人,概率差一点。德州扑克也更好玩:未来的不确定性,以及博弈。
在n人的游戏中,发n副牌,最大的1副牌的类别的概率分布:
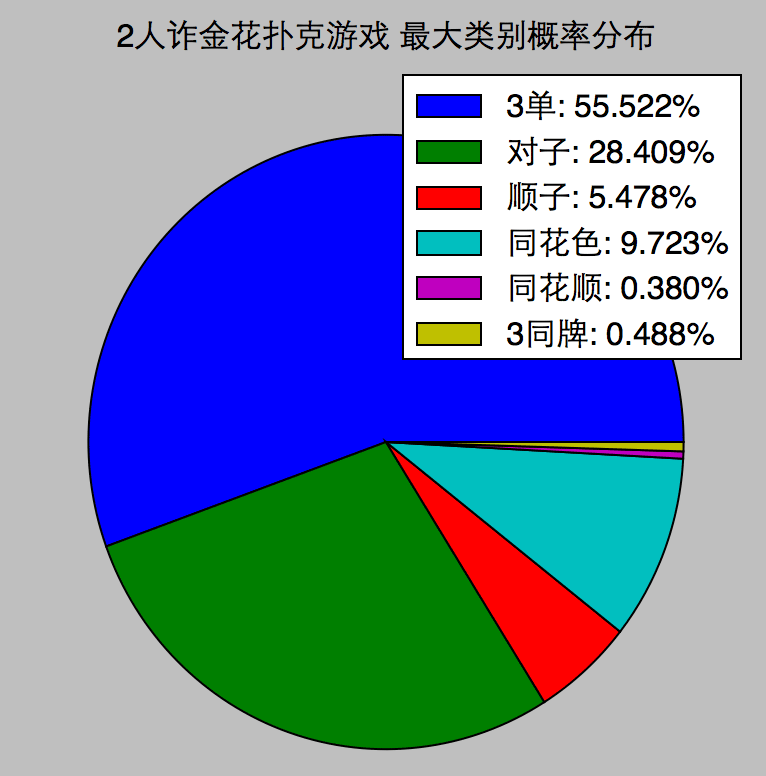

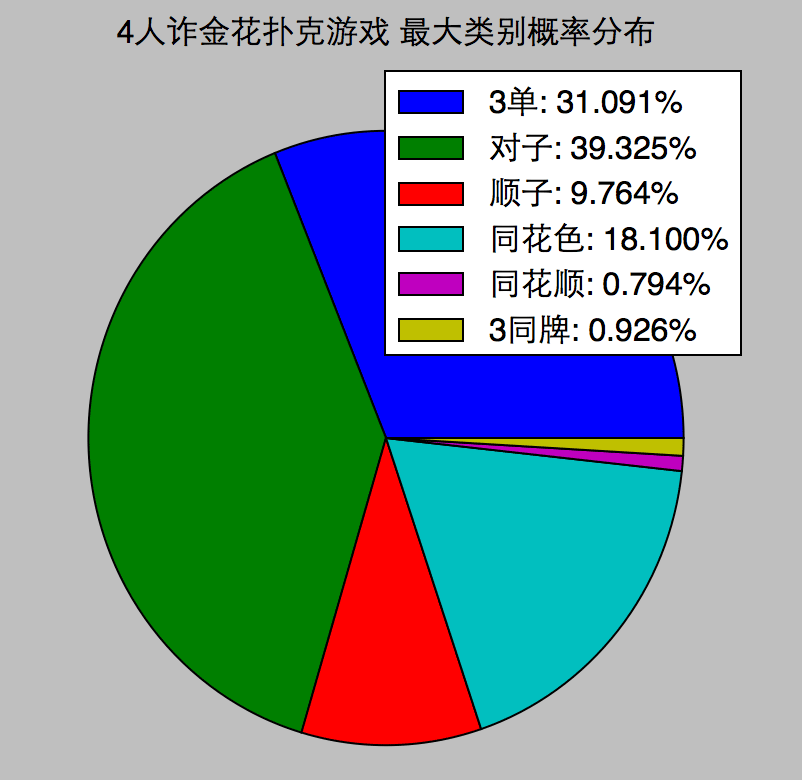
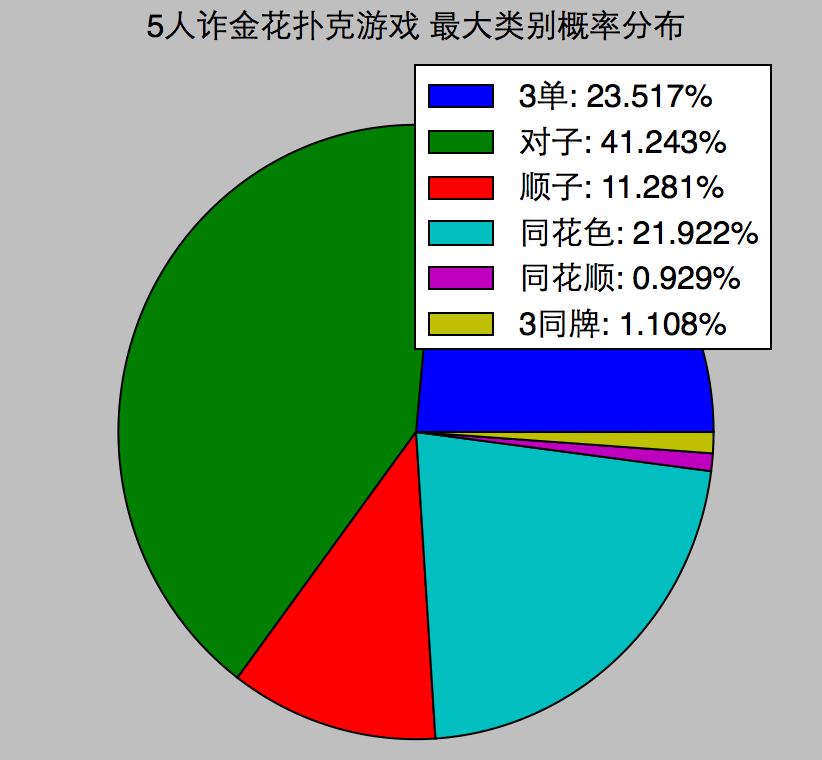

发牌:一副牌,先洗牌,再从中抽出numhands份,各n张牌
def deal(numhands, n=5, deck=[i + s for i in '23456789TJQKA' for s in "SHDC"]):
"Shuffle the deck and deal out numhands n-card hands"
random.shuffle(deck)
return [deck[n * i:n * (i + 1)] for i in range(numhands)]计算牌面类别
def jinhua_rank(hand):
groups = group(["--23456789TJQKA".index(r) for r, s in hand])
counts, ranks = unzip(groups)
ranks = sorted(ranks, reverse=True)
straight = len(set(ranks)) == 3 and (max(ranks) - min(ranks) == 2) # 顺子
flush = len(set([s for r, s in hand])) == 1 # 同花
if counts == (3, ): # 3各牌,一样
return 8, max(ranks)
elif straight and flush: # 同花顺
return 7, max(ranks)
elif flush: # 同花
return 6, ranks
elif straight: # 顺子
return 5, max(ranks)
elif counts == (2, 1): # 一对
return 4, kind(2, ranks), ranks
else: # 3单
return 3, ranks辅助函数
def group(items):
groups = [(items.count(x), x) for x in set(items)]
groups.sort(reverse=True)
return groups
def unzip(pairs): return zip(*pairs)作为一个网名,每天花不少时间浏览网页,由于某些原因,某些网站,在某个国家访问起来有困难。让人泪奔。采用过的方法,有如下几种:
另外最近打算加入一家创业公司,需要全网抓数据,并分析。数据也是对方的宝贵资源,不会轻易让你抓的,会通过各种方式封杀:比如ip rate limiting和user rate limiting等。要和对方斗智斗勇。
今天周末,早上起床后,想着:我应该要解决这两个问题,要干净利落,透明。
代理的代理,对代理进行负载均衡
可以写一个程序,它自己是一个HTTP代理服务器,但相对于一般的代理服务器,它有几个特点:
这样,它既是一个上网加速器,还能帮我透明畅游海外,并且减轻 crawler维护多代理,进行代理切换的工作。
小文件整体cache到redis,大文件metadata存redis,文件存硬盘。呵呵,这样可以从硬盘上收割无数图片和视频,算是额外收获了。
有点意思。
上周末开始编码,通过实际写code,来验证可行性。HTTP 代理服务器比较简单,HTTP,SOCKS代理协议也比较容易实现。搞了几个小时,程序基本work,可以做到浏览twiter,并且上youku也很快。
完善code,让程序更强壮。还有cache到硬盘的图片,好好规划一下,方便收割。
周五在公司时,继续处理推荐相关的code,做物品之间的相似度矩阵计算:通过<用户,物品>矩阵,可以计算出物品(item)两两之间的相似度,生成相似度矩阵,它是协同过滤的基础数据。对每个物品,仅保留与它最相近的120个物品,以及相似度。程序用C++写的, 加上用手工优化的hashmap,多核心同时计算,跑满8个CPU,2分钟左右可以算完600万左右的item的相似度计算。
算完后,相似度关系存为binary的文件(为了快速load)。binary仅对机器友好,对人不友好。得想办法让人可以方便得查看。打算用tornado做一个web界面,可以随便点击查看,这样也给展示更详细得信息提供了可能性:物品以ID表示,如团购项目ID。web工具,可以通过查询数据库,显示团购项目的详细信息,如标题,价格,品类,销量,商家,地址等。这个工具能方便我了解数据,培养sense,以及算法排查,领导查看也方便(相比于给领导一个binary文件,似乎给一个可以点击的URL靠谱一些)。
由于相似度文件1G多一点(binary),C++ load到内存后,RAM在1.5G内。知道python耗内存,但开发机有16G内存,按照Python比C++多耗10倍计算,程序也能跑下来。基于这个考虑,快速coding。C++load时,耗时在2s内,python慢悠悠的,30s还没有见停。浏览了会儿Hacker News。感觉机器卡:机器在辛苦的swap,Python进程已耗掉了12G+内存。果断kill -9。
Python耗内存,早有心理准备,但一个数量级的内存跑程序还困难,还是出乎了意料。
相似度在文件和内存都是map的形式:
# item_id 以及和它相似的 items,以及相似度score
item_id => (item_id, score)+(item_id, score)在C++里面是一个struct:
struct IdScore {
int id;
float score;
};
# 在内存中,耗掉8bytes
sizeof(IdScore) => 8C++通过mmap文件,通过强制类型转化,把文件中bytes转成了IdScore array。简单快速。
Python没有那么方便,需要通过struct.unpack 成tuple。
相对与C和C++里面的sizeof, Python里可以则是sys.getsizeof。
import sys
sys.getsizeof((1, 1.0)) # 72有些出乎意料,tuple算是很节约的了,也需要72 字节,是C++的9倍。
print sys.getsizeof([1, 1.0]) # 88 list。 list比tuple "贵" 一些
print sys.getsizeof(1) # 24 int。int不便宜。
print sys.getsizeof("") # 37 empty string。空字符串也要37 bytes,不便宜。
print sys.getsizeof("abc") # 40 string with 3 chars
class IdScore(object):
def __init__(self, id, score):
self.id = id
self.score = score
# 64。貌似比tuple少一点。那是假象,每个IdScore对象还包含一个__dict__
# getsizeof 算 __dict__8个字节(一指针),但__dict__是独享,需要加进去
# 可以通过__slots__ 节约 __dict__开销
print sys.getsizeof(IdScore(1, 1.0))数字1耗掉了24字节,空字符串耗掉37字节。
Python 的 int 实际上是一个 struct PyIntObject ,intobject.h#L23
typedef struct {
PyObject_HEAD
long ob_ival;
} PyIntObject;
/* PyObject_HEAD 的定义,在 https://github.com/python/cpython/blob/2.7/Include/object.h#L65 */
/* Define pointers to support a doubly-linked list of all live heap objects. */
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;两个指针,一个long,难怪有24bytes。
Python的其它对象也有类似的struct结构(至少有PyObject_HEAD),不便宜。
虽然Python多用了很多珍贵的内存,但开发速度,能节约很多宝贵的时间(用少量的money换时间,早实践了。2年前为自己配的台式机,果断上i7 2600,16G。今年初入的Macbook Pro retina也是16G的配置,貌似是非定制化的顶配)
能快速prototype,验证想法是非常重要的。
一般情况下,程序的优化是可以通过重新设计数据结构达到的。这也不例外。想到了一个很简单的优化,让python也能用不到2G内存,处理这堆数据了:
unpack 到内存了。struct.unpack 得到和它相似的其它 items,以及score